on
CodeReviewGPT系列(二):魔法打败魔法,说说 prompt 优化
到了 CodeReviewGPT 的第二期分享了(自己鼓掌👏)
一个好消息和一个坏消息:
坏消息是,这一期技术成分很低,玄学指数很高。
好消息是,玄学看起来更有趣些,只是很难解释。
先说说背景
与其说是背景,更像是解释一下这篇文章诞生的原因。
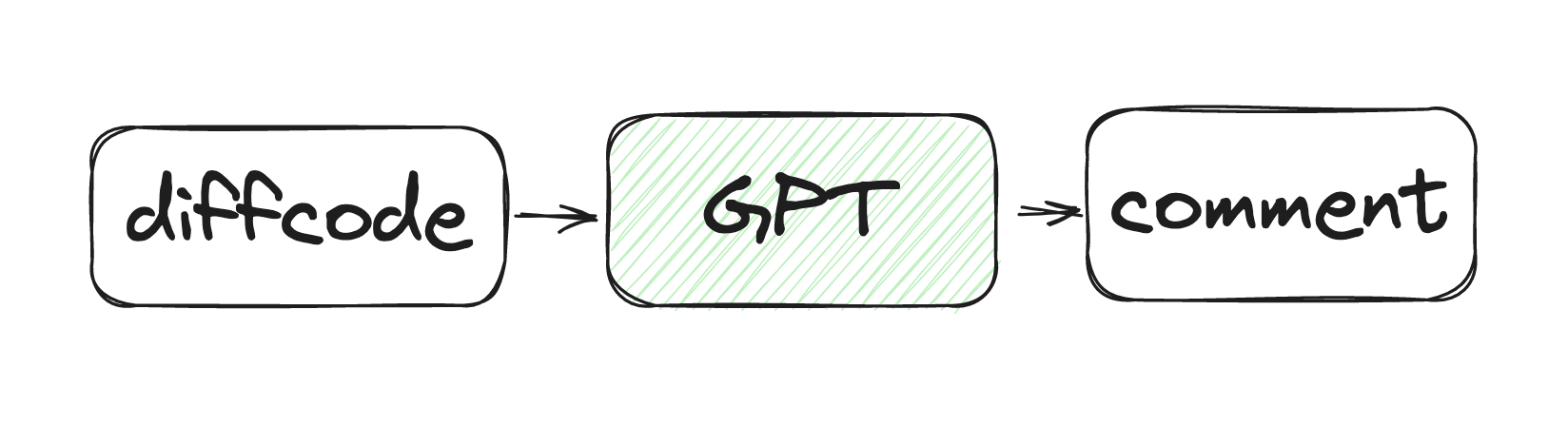
在第一期: CodeReviewGPT 工作流程的分享中,有说到 CodeReviewGPT 的工作流程非常简单,仅三步。
但是,这一切的前提,是 GPT-3.5 模型 (也可以强行理解成chatGPT) 他能够按照要求,完成对代码的评论,并输出结果。
“按照要求” 这四个字,就是这篇文章想要传达的东西。
该如何给 GPT-3.5 提要求???如何让 GPT-3.5 按照要求回答问题???
CR 是典型的补全场景
很多小伙伴应该都用过 ChatGPT 。使用场景非常之简单(不包括后续出现的Code Interpreter),就是对话,或者说聊天。
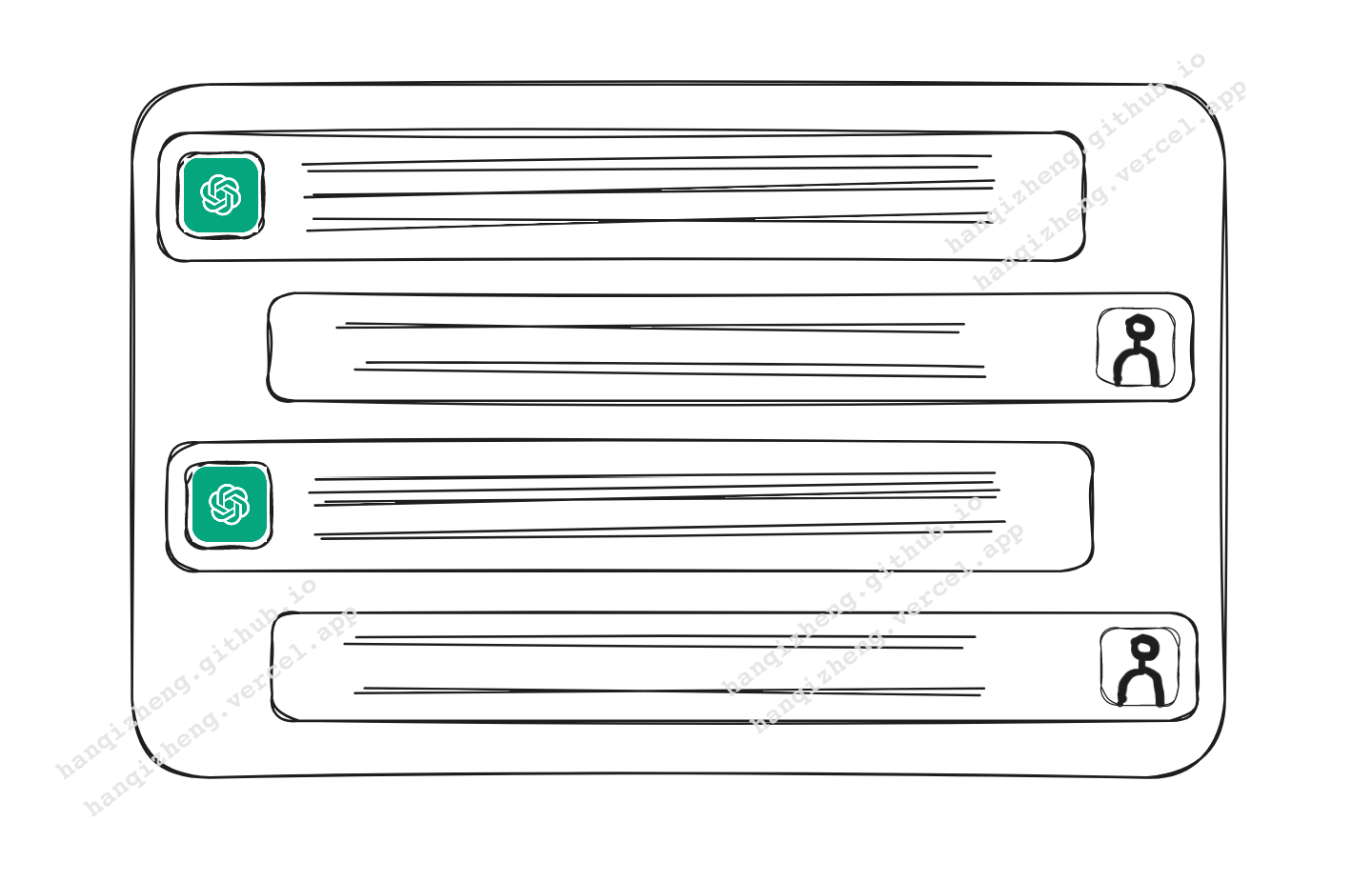
但是在 GPT-3.5 模型所对应提供的 API 中,是有两种类型的 API:
- chat: Given a list of messages comprising a conversation, the model will return a response.
- completions: Given a prompt, the model will return one or more predicted completions, and can also return the probabilities of alternative tokens at each position.
Completion - 补全
跟 chat 模式不同的是,补全模式仅限一次对话,也就是用户只会发出一句 prompt,GPT 也只会回复一次答案,然后结束。

是不是发现, CodeReview 这个过程,就是一次次的补全呢?所以说是典型的补全场景。
为什么说是玄学?
因为 GPT-3.5 这个模型是一个黑盒。

就像调用一个函数,如果我们知道函数的具体实现,那么在 debug 的时候会很容易知道错误在哪里。
但是,面对 GPT 我们只能丢一段话进去,完全不知道会得到些什么。所以说,整个过程就变成了玄学。
为了防止 CodeReviewGPT 的回答过于随机,要做的就是不断的通过各种方式优化 prompt 。
prompt优化平时都在做什么?
如何对 prompt 进行优化,我会以几个场景来展示。
太多无用 comment
有的 MR 收到了 130+ 条的 comment,然后没有一条是有用的。我知道这样的结果确实是很恼人。
其实解决 comment 太多,还准确率低的问题,是很多举措一起作用生效的。为了契合今天的主题,我们只关注 prompt。

最开始的promtp非常零散,可以简单到一句话“帮我review这段代码”。
没有任何的约束,CR 规范输入到 GPT,他只能根据毕生所学,自由发挥。

在 prompt 中明确的添加 CR 的规范之后,要求 GPT 仅关注规范内提到的问题,效果就好非常多了。(prompt中要配套添加严格遵守规范 CR 代码的提示)
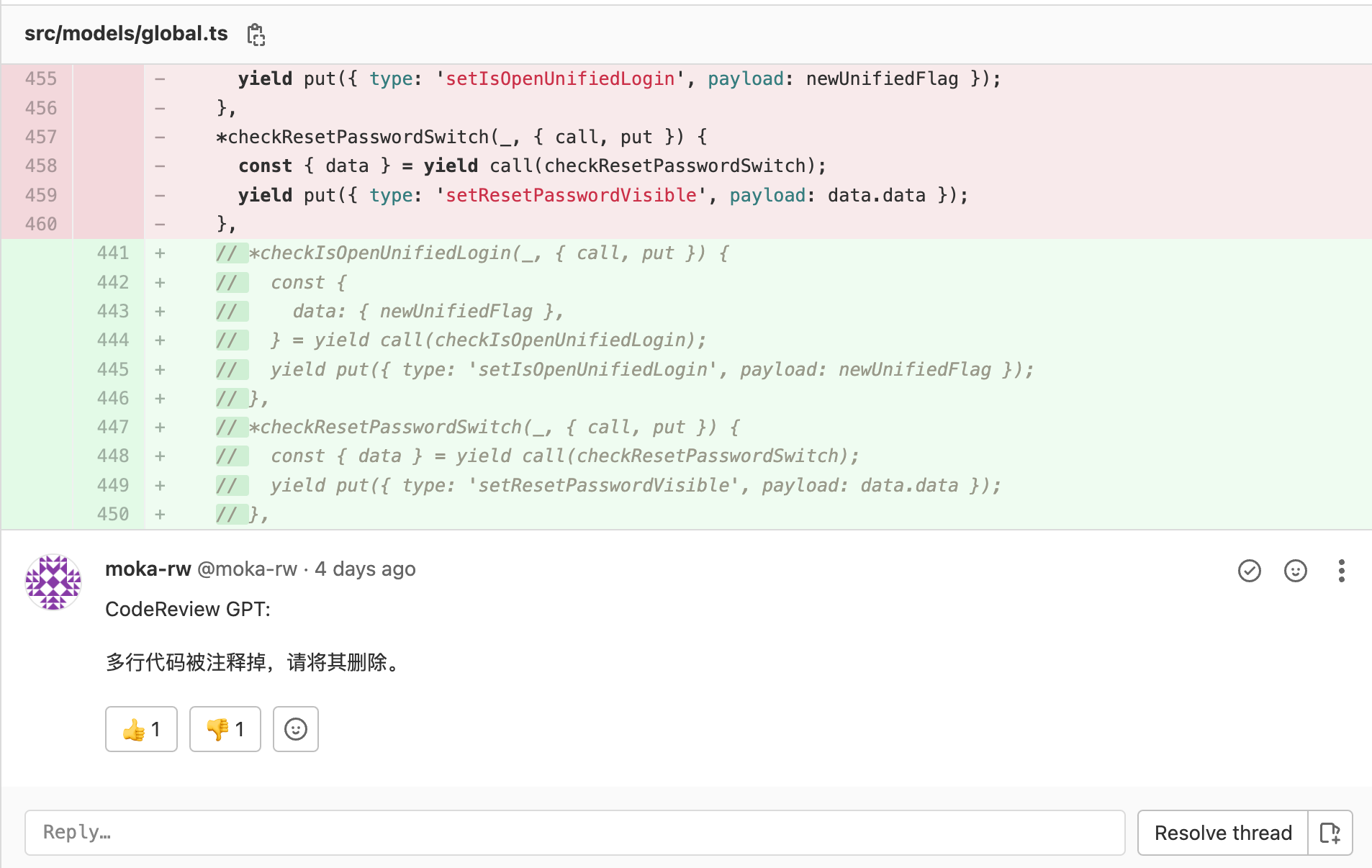
对一段注释的每一行进行评论
先前遇到的一个场景, CodeReviewGPT 对着一段多行注释展开了猛烈攻击,足足评论了 18 条完全相同的 comment(掀桌.jpg。
解决这个问题,在prompt上做了相当大的改动。
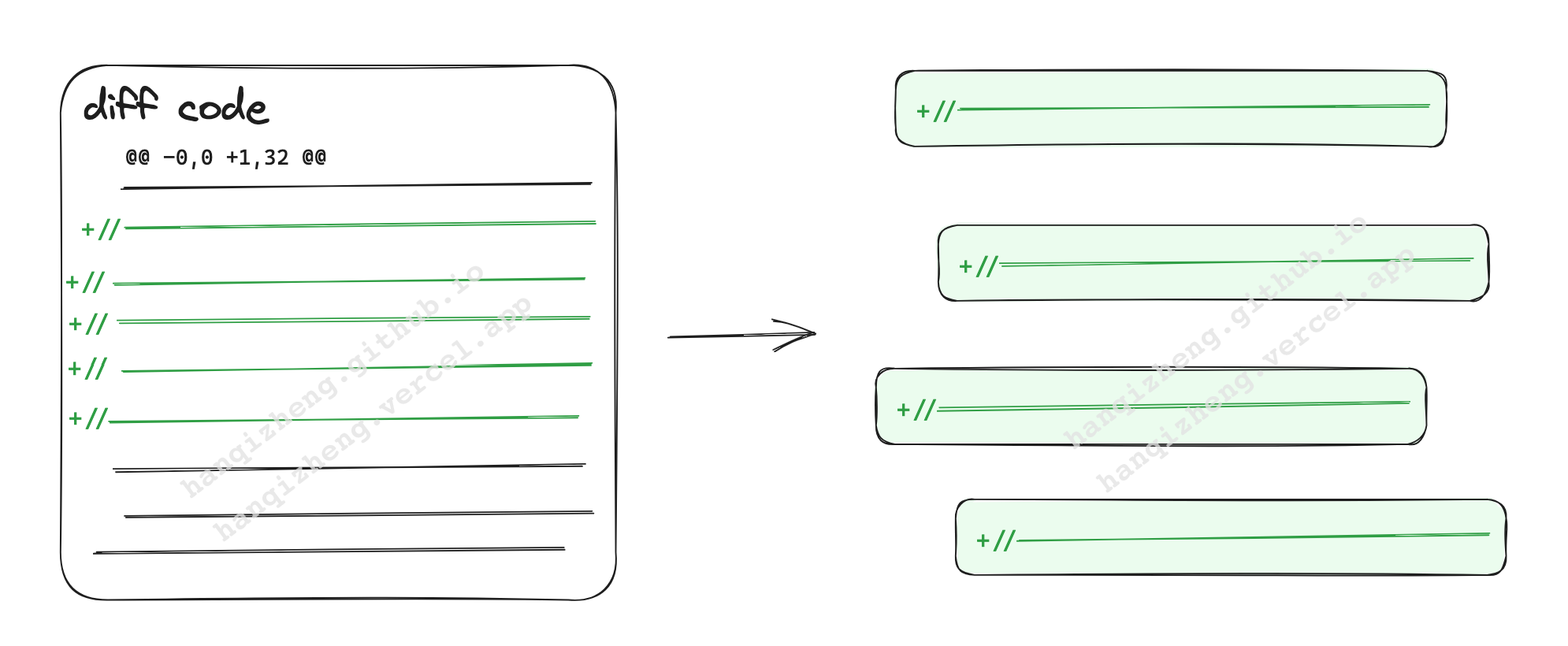
原先的 prompt 保留了 diff code 的原有格式,也就是携带了很多标注 diff 的信息,如 diff 行标, ‘+’ / ‘-‘ 行。
然后根据 GPT-3.5 返回的结果猜测,因为 diff 的 ‘+’ / ‘-‘ 行信息, ‘+’ / ‘-‘ 符号对 GPT 理解这段代码有影响。
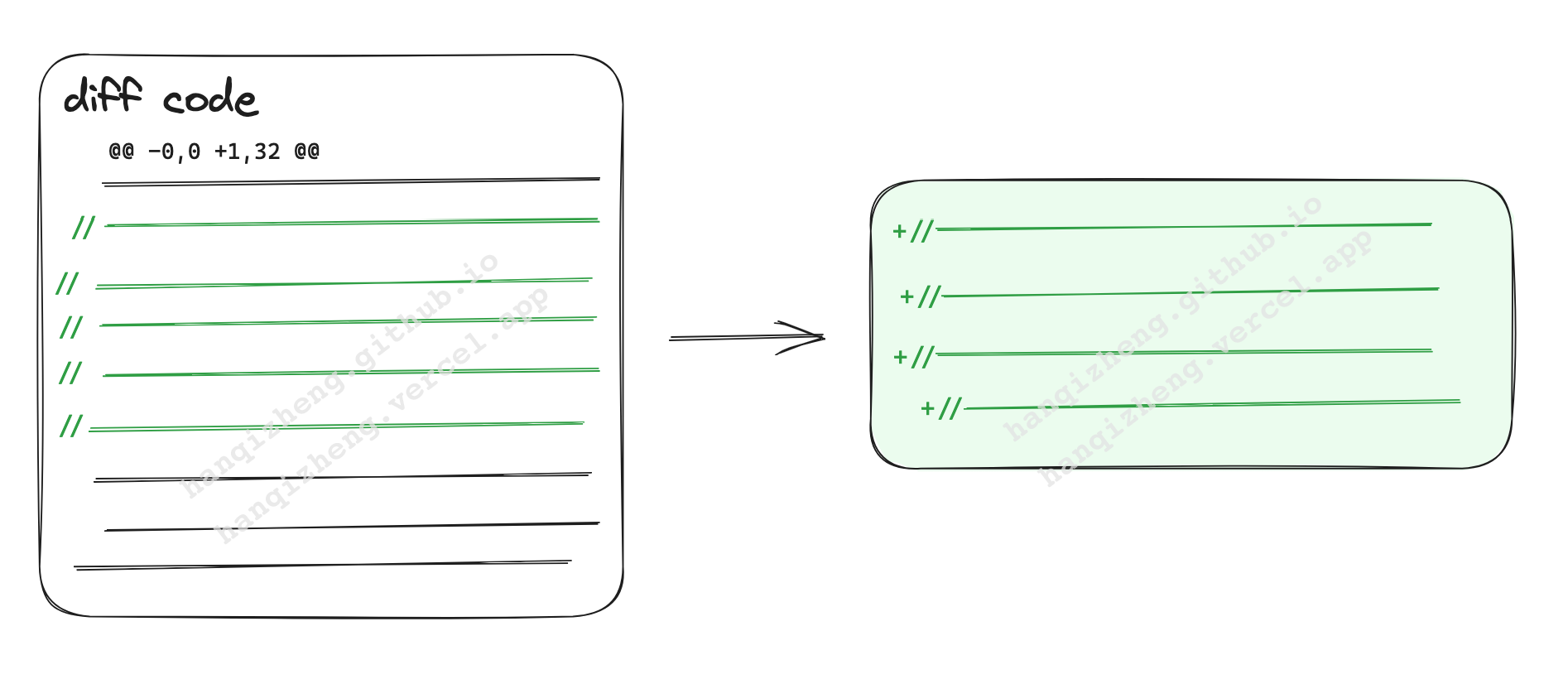
把 diff code 进行处理,去掉所有标识 diff 的信息,只保留原有的代码(注意这里我把所有 删除 的代码也都过滤掉了)。
经过这样处理的 code 放入 prompt 中发给 GPT,得到的回复效果就很好了。
few shots 效果好于 zero shot
这里的 few shots 和 zero shot 是指给 GPT 的 prompt 中是否携带一些解释性的例子🌰。
在CR过程中,CodeReviewGPT 总是在判断 magic string(number) 上出现错误。
特别是在判断魔法字符串上,它会把常量等良好的代码误认为魔法字符串。
一开始, prompt 只有一句 “如果代码中有魔法字符串或魔法数字,请评论并警告。”
GPT 只能按照自己的方式去判断什么事魔法字符串。

为了修改这个问题,我在 prompt 中给出了几个特定的例子,例子都非常简短,甚至仅仅是伪代码。
效果却好了很多,GPT 会掠过一些之前会经常犯错的地方。
感受
为了让大家更好的理解,我并没有贴出任何详细的代码片段,仅抽象其中的优化方式。
但是看完三个案例的你,是不是觉得,一切都发生的莫名其妙,仅仅是修改了几句跟 GPT 的聊天内容,问题就看似解决了。
没错,面对一个黑盒模型,唯一能与它沟通的路径就是 prompt(还有其他方式,这里的唯一仅指目前的CodeReviewGPT)。
这也是为什么整个开发过程充满了不确定性,而解决方式又看似用魔法打败了魔法。