on
n8n真的很好用
尝试用n8n搭建自动化流程,这个低代码交互是我见过的特别好用的一款了。
What is n8n?
n8n 是一个免费的和开源的工作流自动化工具,你可以用它来连接各种应用和服务。其名字是 “node to node” 的缩写,这反映了其设计理念,即帮助用户在各种节点(也就是应用和服务)之间创建工作流。
n8n 允许你通过拖放和配置节点来设计工作流,每个节点代表一个应用或服务,如 Google Sheets、GitHub、Slack 等。每个节点可以执行一项任务,如获取、发送、更新数据等。这样,你可以自动化一系列任务,如将 GitHub 的新问题发送到 Slack,或将 Google Sheets 的数据更新到数据库。
n8n 的一个显著特点是其公开和可扩展的设计。用户可以创建自己的节点,以连接到尚未由 n8n 支持的应用和服务。这使得 n8n 非常灵活,并能适应各种自动化需求。
需要注意的是,虽然 n8n 是开源的,但其也提供了商业版本,包括云版本和服务器版本,这些版本提供了额外的功能和支持。
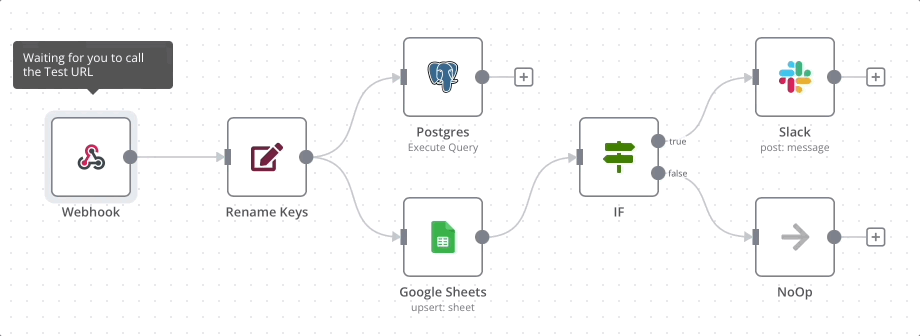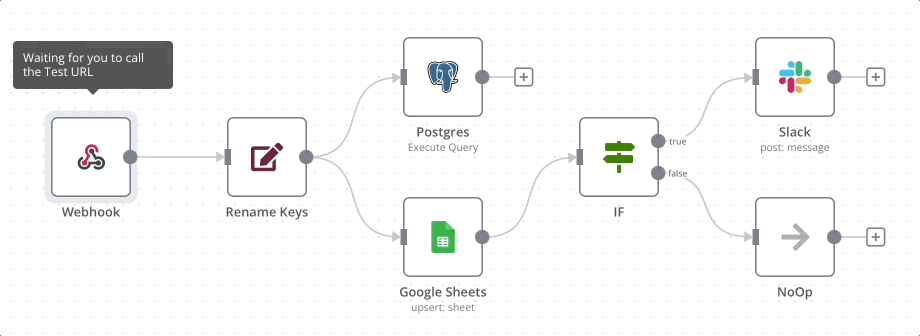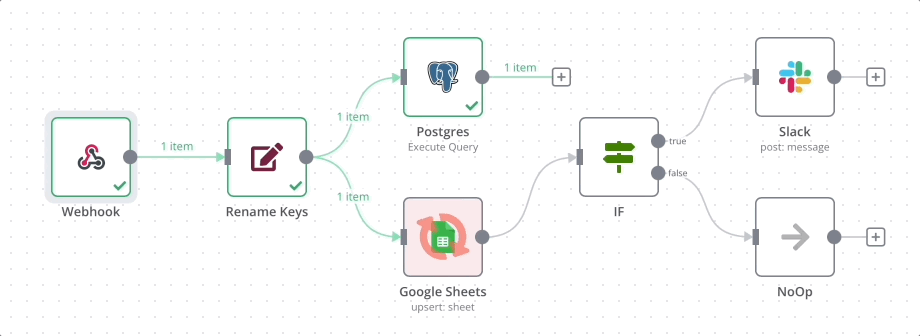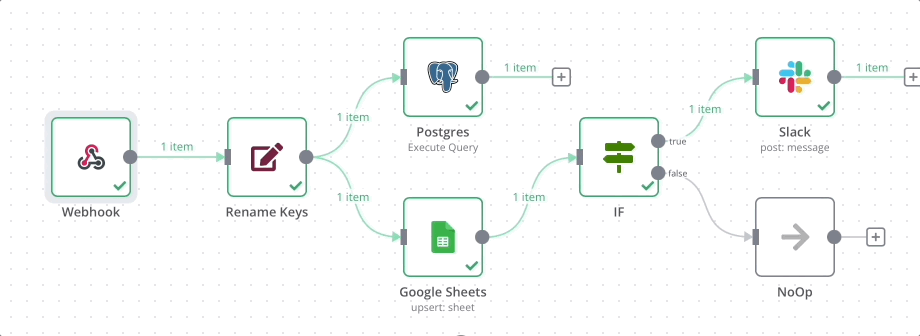
尝试用n8n搭建一个自动化流程
尝试用n8搭建一个自动化生成周报内容的场景。
为什么选择周报场景
周报场景在n8n中的配置涉及到 jira / gitlab / wiki等,可以很好的展示n8n的用法 本身在编写一份周报时,大家要做太多繁琐性的操作了,符合繁琐场景 周报场景存在一定的汇总摘要要求,可以对AI的汇总摘要能力进行验证
为什么选择n8n
主要有两点原因 n8n流程搭建简单易懂,封装了很多其他平台相关的操作,比起写代码这个会更加方便易上手。
n8n是能够被chatGPT识别的一个开源自动化流程搭建工具,这就意味着存在与chatGPT达成合作的可能性。
AI能做些什呢?
chatGPT会用n8n
n8n的常规搭建方式,就是像低代码平台一样,拖拽想要的节点,配置节点所要完成的操作,最终执行流程。
但是对于一个刚接触n8n的人来说,直接想要搭建一个符合自己预期的自动化流程还是有一定的成本(即使n8n的交互设计我个人感觉已经很简单明了)。
因为chatGPT是识别n8n的,所以想尝试通过描述自己想要的流程,让chatGPT可以帮我们直接搭建。
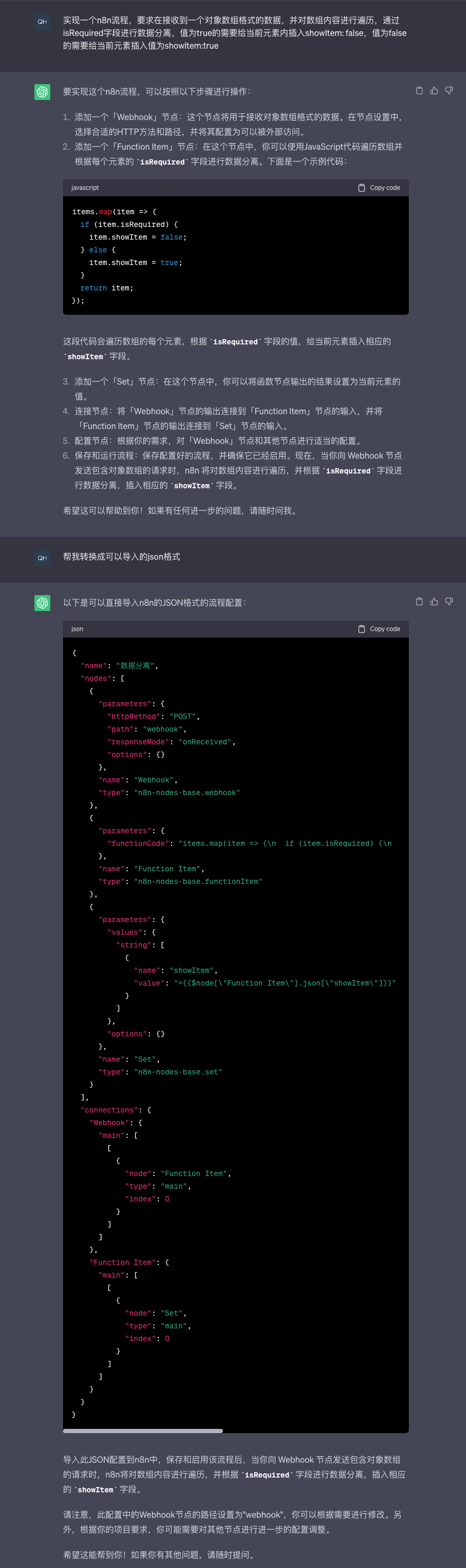
但是有时候的答案存在问题,并不能直接使用
结论:
- 在一些描述下gpt-3.5是能够帮助快速生成n8n流程并完成导入的
- 对描述的要求高,涉及到一些复杂场景或者需要给节点进行一些配置的场景就会出现生成的json无法直接导入的问题
- GPT-3.5有时候还是会胡说
- GPT-3.5了解到的n8n知识老旧概率很大,这也是无法直接拿来使用的一个重要因素
对比GPT-4:
- GPT-4因为无法进行规模化使用从而无法落地,所以仅供效果参考,没有实际意义
- GPT-4因为存在联网功能,可以学习到最新的n8n配置方式,json也大概率可用。
n8n也支持OpenAI
n8n也内置了一些与OpenAI的交互,文本、图片、聊天三大类。需要配置自己的OpenAI token。
这里我没有选择直接用n8n内置的OpenAI相关操作,因为直接用会有各种网络上的问题与限制。我选择用公司内部提供的GPT-3.5的api。
AI帮忙汇总周报内容
完成了流程搭建中数据获取的一部分之后,接下来就是靠AI帮我们汇总生成周报物料的阶段了。在这个过程中因为手里有大量的数据,该如何让AI使用?
AI提取jira关键字段信息
我们现在拿到了若干Jira的数据信息,但是其中冗余了很多暂时用不到或者没办法直接使用(值为null、字段key意义不明确无法确定代表什么的字段)。
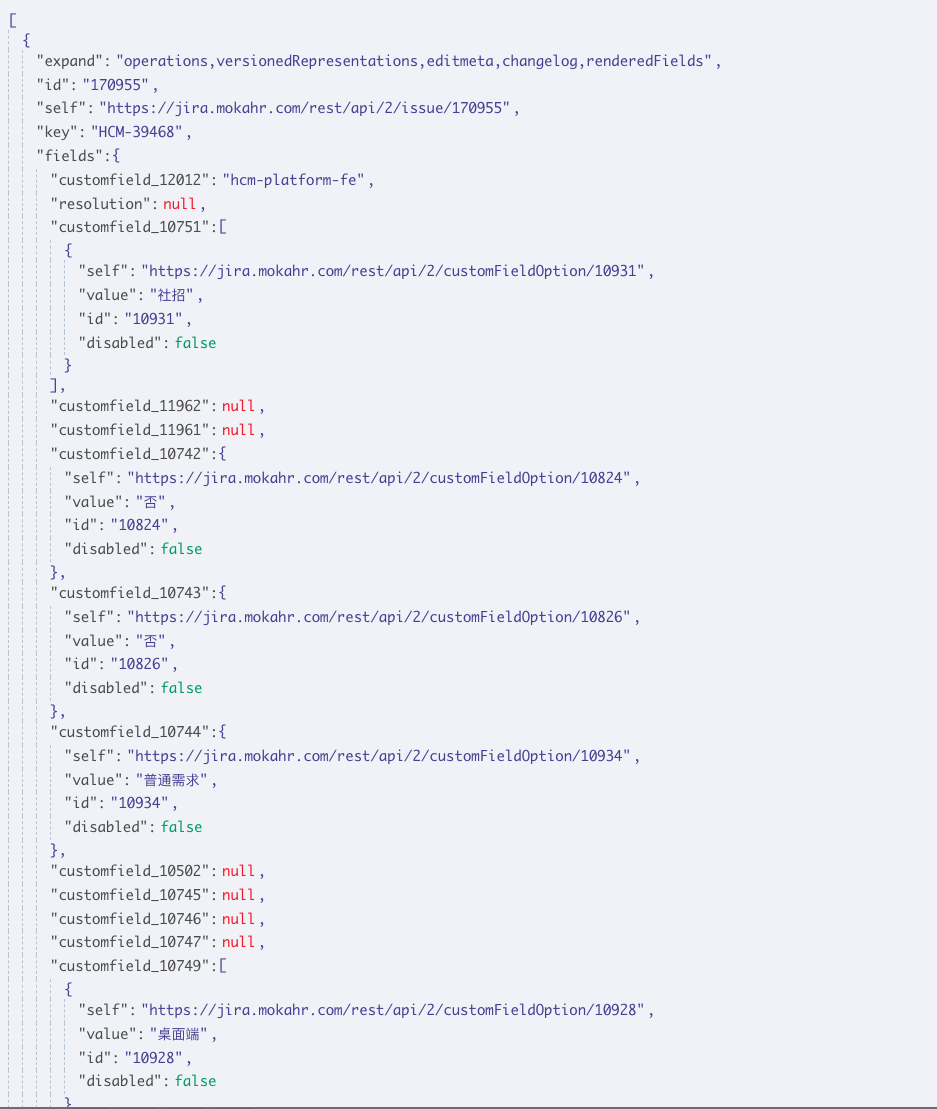
我希望能够提炼出描述jira的关键字段信息,而不是直接携带大量的冗余信息来完成后续的prompt。这个提炼字段的过程,尝试用AI来帮助我。
进行一次 text completion(这里使用的是目前公司内部的gpt-3.5模型接口)
// prompt
这是若干jira中一个具体jira的相关信息
我希望能从若干数据中提取出用于描述jira的关键字段信息,并完成汇总输出。
输出的结果
[
{
"code": 0,
"msg": "success",
"output": "具体需要提取哪些关键字段信息需要根据jira的具体情况来决定,以下是一些可能需要提取的信息: 1. Jira编号:每个Jira都有一个唯一的编号,通常以项目名缩写和数字组成,如PROJ-1234。 2. 标题:Jira的标题,通常会简明扼要地描述这个Jira的内容。 3. 描述:Jira的详细描述,通常会包含更多的细节和信息。 4. 分配人:这个Jira被分配给了哪个人或团队来负责解决。 5. 优先级:Jira的优先级,通常会根据紧急程度和重要性来评估。 6. 状态:Jira的当前状态,如待处理、处理中、已完成等。 7. 创建时间:Jira创建的时间。 8. 更新时间:Jira最后更新的时间。 根据这些关键字段信息,可以进行汇总输出,例如生成一张表格,每行代表一个Jira,每列代表一个字段信息,方便查看和管理。"
}
]
可以看到输出的结果很不理想,其实我所需要的,是一个精简过的 JS 对象,而不是一串对关键字段的描述和解释。
改进过的prompt
// prompt
这是若干jira中一个具体jira的相关信息
我希望能从若干数据中提取出用于描述jira的关键字段信息
(关键的字段信息例如:jira编号,jira描述等等,
过滤掉值为null或字段含义不明确的字段,并完成汇总输出。
我希望输出的结果依然是 js 对象,只是过滤掉一些无用字段后的精简的 js 对象。
得到的结果🤦
[
{
"code": 0,
"msg": "success",
"output": "很抱歉,由于提供的信息过于模糊,我无法为您提供精确的答案。能否提供更具体的数据样例或说明,以便我更好地理解您的需求并提供帮助。"
}
]
继续改进
// prompt
这是若干jira中一个具体jira的相关信息
帮我提取出jira的关键信息字段,并返回精简后的js对象。
我需要你返回的对象中,至少包括这个jira的编号、描述、概要或title、bug类型。
具体对应的字段需要你推断得出。
我希望输出的结果依然是 js 对象,只是过滤掉一些无用字段后的精简的 js 对象。
结果,比较满意👏
[
{
"code": 0,
"msg": "success",
"output": "{\n \"id\": \"170955\",\n \"summary\": \"【薪酬】修复薪酬核算第三步图表类型选择样式错误\",\n \"description\": \"薪酬核算第三步图表类型选择样式错误\",\n \"issueType\": \"UI Bug\"\n}"
}
]
走到这里其实已经可以初步看出AI是能做这件事情(从大量信息中提取关键字段)的。但是输出效果还是不太能够供后续的节点使用,主要原因有两点: 产出的数据结构依然是一个stringify的字符串,没办法直接供后续的workflow node使用 产出的字段也不是特别固定,这样会导致数据不可控,让后续需要完成分析工作的节点所对应的产出变得更随机。
尝试使用一个相对公式化的prompt

这个prompt方法按照特定的一个模版: 角色 (role)、任务 (task)、输出格式 (format)来进行prompt,这样chatGPT会输出相对规整的答案。
这次我调整了一下接口的调用方式,因为本身输入的数据是一个数组,调用方式由: 仅调用一次 -> 每个元素调用一次
这是本次的prompt
// prompt
当前数据
// role & task
请你作为当前数据的使用者,对当前数据进行提炼汇总,要求过滤掉不具备提供jira描述信息(什么是jira的描述信息字段的判断标准需要由你自行决定)。
// format
请以一个js对象的格式进行输出,例如:
{
property_one: xxx,
property_two: xxx,
// other properties
}
输出结果如下
[
{
"code": 0,
"msg": "success",
"output": "{\n \"id\": \"170955\",\n \"key\": \"HCM-39468\",\n \"summary\": \"【薪酬】修复薪酬核算第三步图表类型选择样式错误\",\n \"description\": \"薪酬核算第三步图表类型选择样式错误\",\n \"status\": {\n \"name\": \"待上线\"\n },\n \"assignee\": {\n \"displayName\": \"韩启正\"\n },\n \"reporter\": {\n \"displayName\": \"韩启正\"\n },\n \"created\": \"2023-05-23T07:12:10.000+0000\",\n \"updated\": \"2023-05-26T07:57:49.000+0000\"\n}"
},
{
"code": 0,
"msg": "success",
"output": "{\n \"id\": \"101922\",\n \"key\": \"SUGAR-399\",\n \"summary\": \"【NewTable】问题修复和功能优化\",\n \"status\": {\n \"name\": \"发布\",\n \"id\": \"10900\"\n },\n \"assignee\": {\n \"displayName\": \"韩启正\",\n \"emailAddress\": \"hanqizheng@mokahr.com\"\n },\n \"creator\": {\n \"displayName\": \"韩启正\",\n \"emailAddress\": \"hanqizheng@mokahr.com\"\n },\n \"project\": {\n \"key\": \"SUGAR\",\n \"name\": \"Sugar Design\"\n },\n \"issuetype\": {\n \"name\": \"故事\"\n },\n \"priority\": {\n \"name\": \"Medium\"\n },\n \"created\": \"2022-02-14T03:29:28.000+0000\",\n \"updated\": \"2023-03-16T09:27:33.000+0000\",\n \"resolutiondate\": \"2022-02-14T07:12:53.000+0000\"\n}"
},
{
"code": 0,
"msg": "success",
"output": "{\n \"id\": \"159914\",\n \"key\": \"SUGAR-762\",\n \"summary\": \"【Sugar】NewTable rowSelction.selectedRowKeys兼容undefined\",\n \"description\": \"NewTable rowSelction.selectedRowKeys不兼容 undefined (type要求必传)\\r\\n\\r\\n一些老旧的js文件使用NewTable容易传入undefined然后白屏。\",\n \"created\": \"2023-02-20T07:35:28.000+0000\",\n \"updated\": \"2023-03-12T08:39:20.000+0000\",\n \"status\": {\n \"name\": \"发布\"\n },\n \"priority\": {\n \"name\": \"Medium\"\n }\n}"
},
{
"code": 0,
"msg": "success",
"output": "{\n \"id\": \"156394\",\n \"key\": \"HCM-34847\",\n \"summary\": \"【薪酬】替换旧Table第二期\",\n \"status\": {\n \"name\": \"已上线\"\n },\n \"assignee\": {\n \"displayName\": \"韩启正\"\n },\n \"reporter\": {\n \"displayName\": \"韩启正\"\n },\n \"created\": \"2023-01-12T08:27:19.000+0000\",\n \"updated\": \"2023-03-12T07:06:23.000+0000\",\n \"project\": {\n \"id\": \"10402\",\n \"key\": \"HCM\",\n \"name\": \"HCM-ALL\"\n },\n \"components\": [\n {\n \"id\": \"11000\",\n \"name\": \"薪酬\"\n }\n ],\n \"description\": null\n}"
}
]
如果我们只关注output这个字段的输出值(很遗憾output貌似输出值类型必然是string,所以数据依然是stringify过的)
输出结果非常满意👍
// 以其中一次提取结果做示例
{
"id": "170955",
"key": "HCM-39468",
"summary": "【薪酬】修复薪酬核算第三步图表类型选择样式错误",
"description": "薪酬核算第三步图表类型选择样式错误",
"status": { "name": "待上线" },
"assignee": { "displayName": "韩启正" },
"reporter": { "displayName": "韩启正" },
"created": "2023-05-23T07:12:10.000+0000",
"updated": "2023-05-26T07:57:49.000+0000"
}
刚才提到的两个点:
- 输出结果是stringify字符串。因为是chatGPT聊天默认输出结果类型为string,目前只能在用之前做一次类型转换 String -> Object
- 输出字段不确定。这一点在完善过prompt之后,每次输出的区别变小,后续的流程本身也没有要明确使用哪个字段,这次的输出即将作为下一个节点的输入继续抛给chatGPT,目前看影响较小。
AI汇总信息生成周报
目前走到了最后一步,我们手里有归纳汇总过的jira、gitlab相关的数据
[
{
"code": 0,
"msg": "success",
"output": "1. 当前有以下jira任务:\n- 【薪酬】修复薪酬核算第三步图表类型选择样式错误 (HCM-39468):https://jira.mokahr.com/browse/HCM-39468\n- 【NewTable】问题修复和功能优化 (SUGAR-399):https://jira.mokahr.com/browse/SUGAR-399\n- 【Sugar】NewTable rowSelction.selectedRowKeys兼容undefined (SUGAR-762):https://jira.mokahr.com/browse/SUGAR-762\n- 【薪酬】替换旧Table第二期 (HCM-34847):https://jira.mokahr.com/browse/HCM-34847\n\n2. 对于bug类别的jira,我们需要分析其响应速度。我将响应时长过长的标准设定为超过7天未解决。根据此标准,我们可以看出SUGAR-762这个bug类别的jira响应时间已经超过了标准,需要给出警告。\n\n3. 最终汇总:\n- 任务类jira:\n - 【薪酬】修复薪酬核算第三步图表类型选择样式错误 (HCM-39468):https://jira.mokahr.com/browse/HCM-39468\n - 【NewTable】问题修复和功能优化 (SUGAR-399):https://jira.mokahr.com/browse/SUGAR-399\n - 【薪酬】替换旧Table第二期 (HCM-34847):https://jira.mokahr.com/browse/HCM-34847\n- bug类jira:\n - 【Sugar】NewTable rowSelction.selectedRowKeys兼容undefined (SUGAR-762):https://jira.mokahr.com/browse/SUGAR-762 (警告:响应时间超过7天)"
},
{
"code": 0,
"msg": "success",
"output": "1. 活动涉及到的任务汇总:\n\n- Feat: NewTable 支持 toolbar ,以及滚动时 toolbar 部分内容吸顶\n- [HCM-39468] 修复薪酬界面样式错误\n\n2. 活动对应的操作汇总:\n\n- commented on: Feat: NewTable 支持 toolbar ,以及滚动时 toolbar 部分内容吸顶 (x6)\n- deleted: [HCM-39468] 修复薪酬界面样式错误\n- opened: [HCM-39468] 修复薪酬界面样式错误\n- pushed new: [HCM-39468] 修复薪酬界面样式错误\n\n3. 用户近一周涉及的任务汇总:\n\n- Feat: NewTable 支持 toolbar ,以及滚动时 toolbar 部分内容吸顶\n- [HCM-39468] 修复薪酬界面样式错误"
}
]
现在让 GPT 帮我们生成周报内容: 经过之前prompt的一些经历,现在第一遍给的prompt已经自认为很详细了
// prompt
这个是当前用户在近一周内在jira 和 gitlab上完成的相关操作汇总。
请根据上述内容,生成一份工作周报汇总,并对本周工作进行总结,标注出一些值得注意和改进的点。
值得注意的是,jira和gitlab的任务汇总来自两个不同的平台,但是本身涉及到的任务可能是一个相同的任务,需要对同一任务的相关信息进行聚合汇总。
确定是否是相同任务可以通过Jira号来判断(jira号格式类似 HCM-1234)
以markdown格式输出
得到的结果
发现结果不是特别满意,周报的格式应该是任务jira链接,任务描述,任务内容这样子,而并非依然按照数据来源进行了内容区分(jira任务汇总 / gitlab任务汇总)
[
{
"code": 0,
"msg": "success",
"output": "## 工作周报汇总\n\n### Jira任务\n\n当前有以下jira任务:\n\n- 【薪酬】修复薪酬核算第三步图表类型选择样式错误 (HCM-39468):https://jira.mokahr.com/browse/HCM-39468\n- 【NewTable】问题修复和功能优化 (SUGAR-399):https://jira.mokahr.com/browse/SUGAR-399\n- 【Sugar】NewTable rowSelction.selectedRowKeys兼容undefined (SUGAR-762):https://jira.mokahr.com/browse/SUGAR-762\n- 【薪酬】替换旧Table第二期 (HCM-34847):https://jira.mokahr.com/browse/HCM-34847\n\n对于bug类别的jira,我们需要分析其响应速度。我将响应时长过长的标准设定为超过7天未解决。根据此标准,我们可以看出SUGAR-762这个bug类别的jira响应时间已经超过了标准,需要给出警告。\n\n最终汇总:\n\n- 任务类jira:\n - 【薪酬】修复薪酬核算第三步图表类型选择样式错误 (HCM-39468):https://jira.mokahr.com/browse/HCM-39468\n - 【NewTable】问题修复和功能优化 (SUGAR-399):https://jira.mokahr.com/browse/SUGAR-399\n - 【薪酬】替换旧Table第二期 (HCM-34847):https://jira.mokahr.com/browse/HCM-34847\n- bug类jira:\n - 【Sugar】NewTable rowSelction.selectedRowKeys兼容undefined (SUGAR-762):https://jira.mokahr.com/browse/SUGAR-762 (警告:响应时间超过7天)\n\n### Gitlab操作\n\n活动涉及到的任务汇总:\n\n- Feat: NewTable 支持 toolbar ,以及滚动时 toolbar 部分内容吸顶\n- [HCM-39468] 修复薪酬界面样式错误\n\n活动对应的操作汇总:\n\n- commented on: Feat: NewTable 支持 toolbar ,以及滚动时 toolbar 部分内容吸顶 (x6)\n- deleted: [HCM-39468] 修复薪酬界面样式错误\n- opened: [HCM-39468] 修复薪酬界面样式错误\n- pushed new: [HCM-39468] 修复薪酬界面样式错误\n\n### 工作总结\n\n本周工作主要集中在Jira任务和Gitlab操作方面。从Jira任务的汇总来看,我们需要更加关注bug类别的Jira的响应速度,避免出现响应过慢的情况。在Gitlab操作方面,我们完成了NewTable的优化和薪酬界面样式错误的修复。在下一周的工作中,我们需要继续关注Jira任务的进展,同时对Gitlab操作进行更加细致的跟进和优化。"
}
]
改进prompt (期间经过无数次改进😭)
// prompt
这个是当前用户在近一周内在jira 和 gitlab上完成的相关操作数据汇总。
请根据上述内容,生成一份工作周报汇总。
我期望周报内容有一下几块:
- 任务汇总
- bug汇总
- 其余工作汇总(如果没有相关数据可以不写这个模块)
- 建议与思考(供用户参考从而产生一些个人的思考)
其中任务汇总、bug汇总等工作汇总是以任务为划分维度的,例如:
任务1描述,任务1链接,任务1本周工作内容
值得注意的是,jira和gitlab的数据可能是对同一个任务的不同内容描述,需要通过jira编号进行任务聚合(jira编号格式类似于 HCM-1234)
jira数据多半是可以描述任务的,而gitlab中的数据多半是这个任务具体的工作内容。
以上任务汇总格式希望按照一个表格的形式汇总展示。
思考与建议希望得到一些关于bug处理警告之类的信息。有助于更好的工作。
相对满意的结果🎉
[
{
"code": 0,
"msg": "success",
"output": "工作周报汇总:\n\n任务汇总:\n\n| 任务描述 | 任务链接 | 本周工作内容 |\n| --- | --- | --- |\n| 【薪酬】修复薪酬核算第三步图表类型选择样式错误 | https://jira.mokahr.com/browse/HCM-39468 | 修复了薪酬界面样式错误 |\n| 【NewTable】问题修复和功能优化 | https://jira.mokahr.com/browse/SUGAR-399 | 改进了NewTable的toolbar和滚动时的吸顶效果 |\n| 【薪酬】替换旧Table第二期 | https://jira.mokahr.com/browse/HCM-34847 | 进行了旧Table的替换工作 |\n\nBug汇总:\n\n| Bug描述 | Bug链接 | 响应时间 |\n| --- | --- | --- |\n| 【Sugar】NewTable rowSelction.selectedRowKeys兼容undefined | https://jira.mokahr.com/browse/SUGAR-762 | 超过7天未解决 |\n\n其余工作汇总:\n\n无\n\n建议与思考:\n\n根据SUGAR-762 bug的响应时间超过7天的情况,需要加强对于bug的响应速度,尤其是对于影响系统稳定性的bug,需进行及时响应和解决。同时,建议在工作中加强沟通和协作,避免类似问题的出现。"
}
]
效果
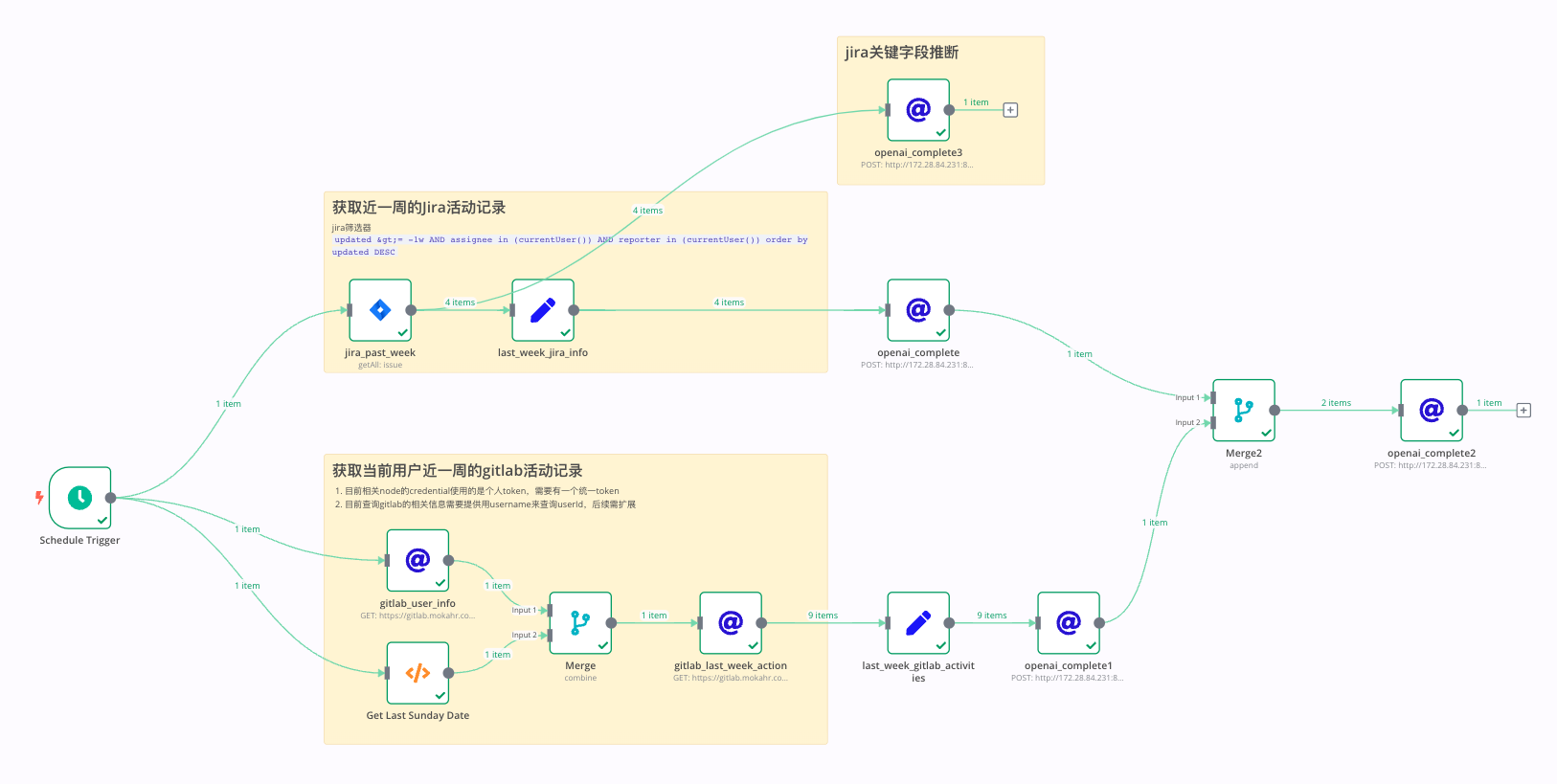
流程描述
获取当前用户近一周的 jira 和 gitlab (目前仅对接了这两个平台)的活动内容。由AI对获取到的内容进行汇总整理,最终输出周报所需的物料(供编写周报使用)或 周报模版。
周报内容截图

TODO: 可扩展补充的功能
- 支持生成的周报满足已有的周报模版
- 支持数据的汇总与归纳也是由AI完成
- 丰富周报的内容,通过完善prompt来汇总得出更多的有用信息字段
- 支持直接写入指定的wiki文档用于复查周报内容或者直接发送邮件
- 寻找流程的通用使用方案而不是每个人使用都需要填一些配置(n8n的局限)
- 与企业微信相关操作的对接
- 搭建好的流程目前是账号维度所以还没办法共享😅,后续康康怎么搞成通用的
- 扩展周报功能,尝试生成以组为单位的团队周报、bug汇总、甚至月报等。
聊聊我的想法
n8n有一定的局限性
在使用n8n构建自动化流程的过程中,还是发现一些配置上的局限性。
- 平台对接需要配置可用token
- 一些付费功能没办法使用比较影响流程配置的灵活性
- 与openai 的 api进行交互时,chat接口的每次调用相当于一次新的conversation,没办法留存context来帮助ai完成逐步学习最终达到目标的效果。目前ai接口全部使用的 /complete
不过n8n是一个开源项目,后续可以通过更改源代码来达到开放功能的效果(手动滑稽
对 prompt 的要求很高
在尝试通过 ai 帮助我们生成一些内容时,对prompt的要求很高,如果描述不清楚或者给定的数据太过笼统,都会很大程度的影响生成的内容。
不过这里可以分享一个小技巧:尽量描述清楚想要的格式,甚至给出示例就会改善效果。9
模型有一定局限性
-
GPT-3.5 因为没有 GPT-4的联网功能,很大程度上会受到仅支持2021年9月之前的知识库的限制,很多涉及到开源项目的新版本的场景都无法直接产出想要的内容。 对文本的汇总生成能力也相对较差
-
我们可以通过更准确的prompt和提供相对丰富的context来解决以上问题(并非完全解决)
还有很多流程可以通过自动化搭建
- 发送周报的场景仅是抛砖引玉。很多实际开发工作中的场景都可以配置出对应的流程,比如:
- 每周的Sentry问题汇总与趋势统计
- 每个迭代的若干gitlab project创建特定分支的MR
- 每次需求创建MR都要在微信群喊一声
- 每个线上BUG都需要手动标记bug原因
- 等等
参考
- n8n文档
- openai - Text completion gitlab rest api