on
NewTable树形数据渲染
经典再现,这次,是 NewTable 的又一 milestone,支持树形结构的数据渲染。
数据处理
读过前两篇的你应该有记着,NewTable 的渲染逻辑是服务于虚拟渲染的。
所以无论是普通模式的 NewTable 还是分组模式,再到现在的树形数据模式,都希望沿用已有的虚拟化计算方式,能减少很多的工作量。
而决定是否能沿用原有虚拟化的逻辑关键,就在于能否沿用基础的渲染逻辑。
答案是肯定的,因为我们有 拍平数据 这一法宝。
注入信息
树形结构有一些特别的地方就是为了后续的渲染和一些交互逻辑更方便,减少循环次数提高性能,尽量保证一次循环就能完成所有额外的拍平数据逻辑,而不需要后续再去循环操作什么。
所以注入的信息主要是为了解决几个树形结构的特有功能点:
- 展开收起
- 拖拽
- 渲染
具体注入的字段有:
interface TreeData {
// ...OriginTreeData
/** 当前节点是否展开 */
isExpand: boolean;
/** 当前节点所在树层级 */
depth: number;
/** 当前节点的父节点引用 */
parentNode?: TreeData;
}
具体每个属性的详细使用方式会在对应功能章节解释。
拍平数据
NewTable 的树形数据拍平使用的是 递归。
拍平以后的数据,就是一个一维数组,可以直接复用 NewTable 原有的渲染逻辑。
唯一的区别就在 树形结构的那一列 UI 渲染逻辑上。
interface TableTreeProps {
// ...other props type
treeHeaderKey: keyof Header[number]['key'];
}
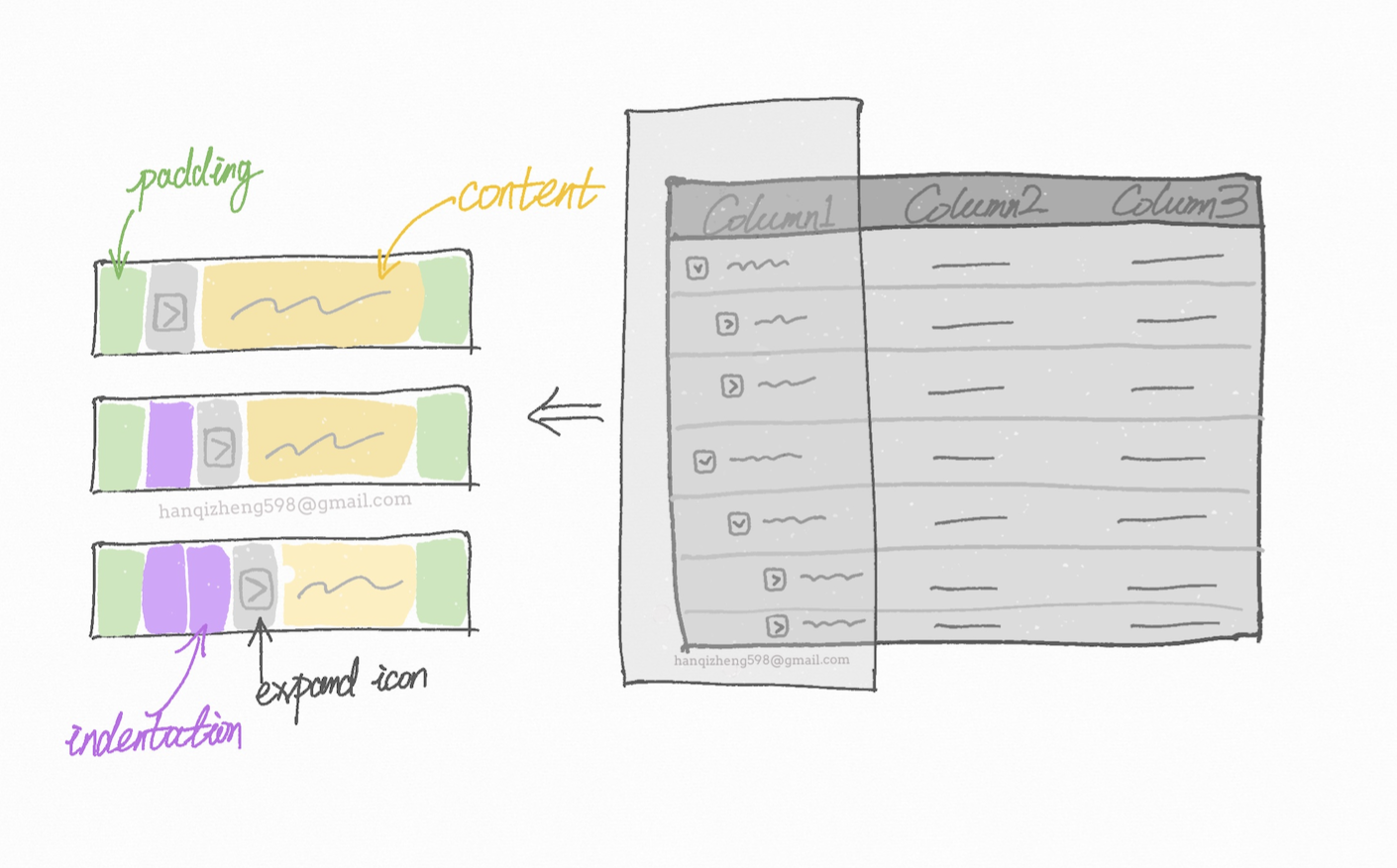
单元格的渲染逻辑其实主要 2 部分:
- 缩进。用于体现出树的层级结构
- 内容。展示树形数据本来要展示的内容。
拍平数据有一定缺陷
拍平数据有一个很明显的缺陷就是会干扰默认 index 作为 rowKey的情况。
不过作为树形数据,本身 index 来作为区分每一行的 key 就是有歧义的。歧义就是遍历方式不同会导致每个节点的index不一样。
解决方案是什么呢?
interface TableProps {
// other props type
rowKey?: RowKey;
}
interface TableTreeProps {
// ...other props type
rowKey: RowKey;
}
应对的策略就是在 props 的定义上就限制 rowKey 作为必填 props。
自适应缩进距离
缩进区域的宽度计算方式,这里就用到了第二个注入的属性depth:
缩进单位宽度 * (当前数据depth - 1)
可以看出来缩进宽度是一个定值,而为了沿用原有的渲染逻辑,树形数据列的列宽依然是通过 header 配置好的,不会自动改变。
那么内容区域的宽度,就会被缩进宽度挤压变小。直到:
树形数据列宽 < 缩进宽度 + 最小内容宽度
说明内容存在溢出,这个时候需要自适应缩进宽度(也就是减小缩进宽度)
减小的计算方法是:
新的缩进单位宽度 = (树形数据列宽 - 最小内容宽度) / 树的高度
树形数据列宽 - 最小内容宽度可以得出留给缩进的最大宽度是多少
再除以 树的高度(其实就是最大的缩进个数) 就能得出新的 单位缩进宽度 了。
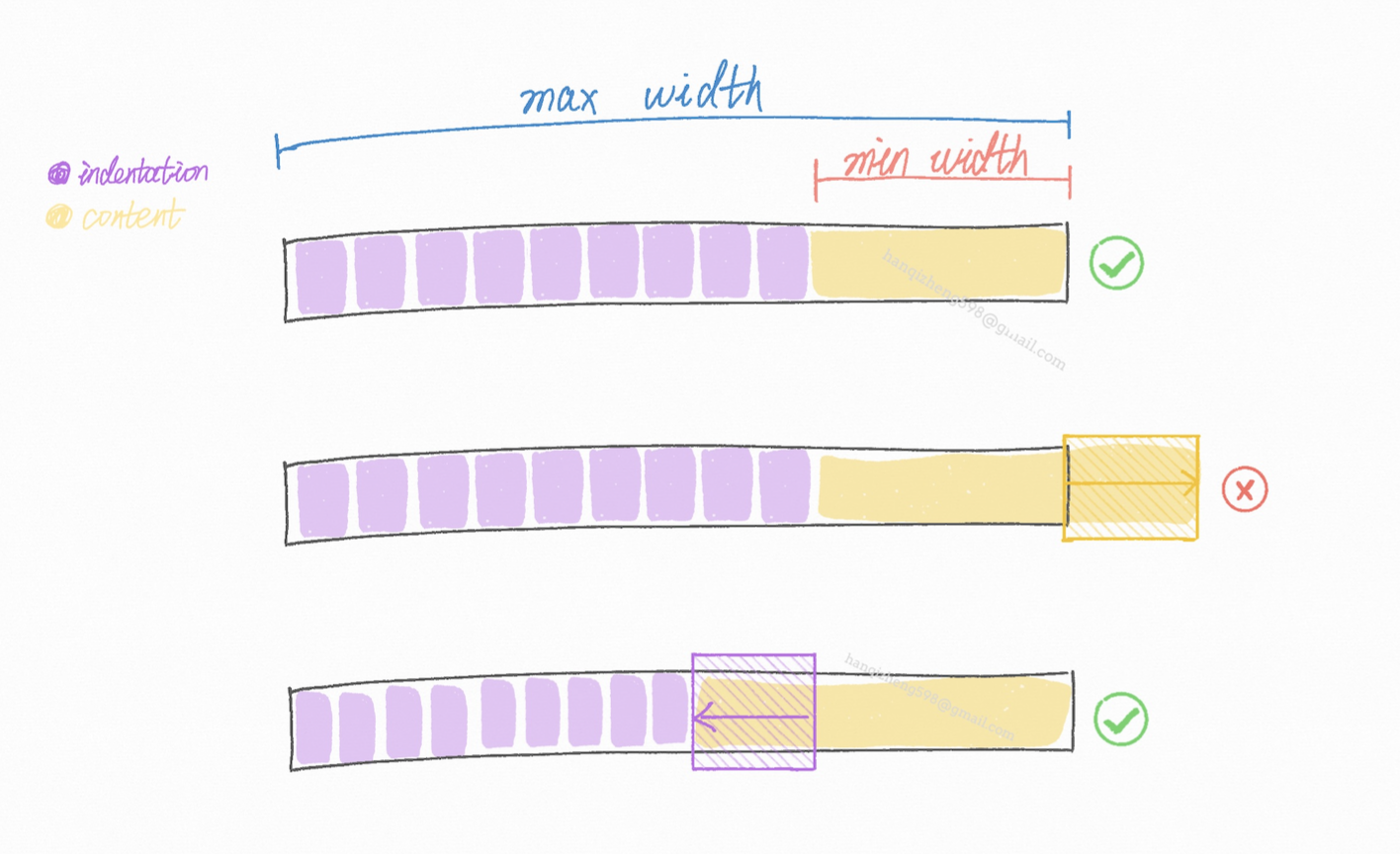
可以看到缩进的份数是不会变的,改变的是 每一份的缩进宽度。
展开收起
展开收起是树的一个基本操作。
对于 NewTable 来说,展开收起就是更新数据,重新绘制。
这个时候就要用上第一个注入的属性 - isExpand
isExpand的功能:
- isExpand的作用是记录。记录展开收起状态。
- 决定相关 UI 的显示。
真正展开收起的状态维护是通过一个Set去完成的 (不得不再次强调一下 rowKey 的重要性)。
const expandedKeySet = new Set();
if (isExpand) {
expandedKeySet.add(expandKey);
} else {
expandedKeySet.delete(expandKey);
}
拖拽
拖拽是树的又一经典操作。
拖拽的实现依然依赖 react-dnd。
唯一的却别就是拖拽触发热区改变了。
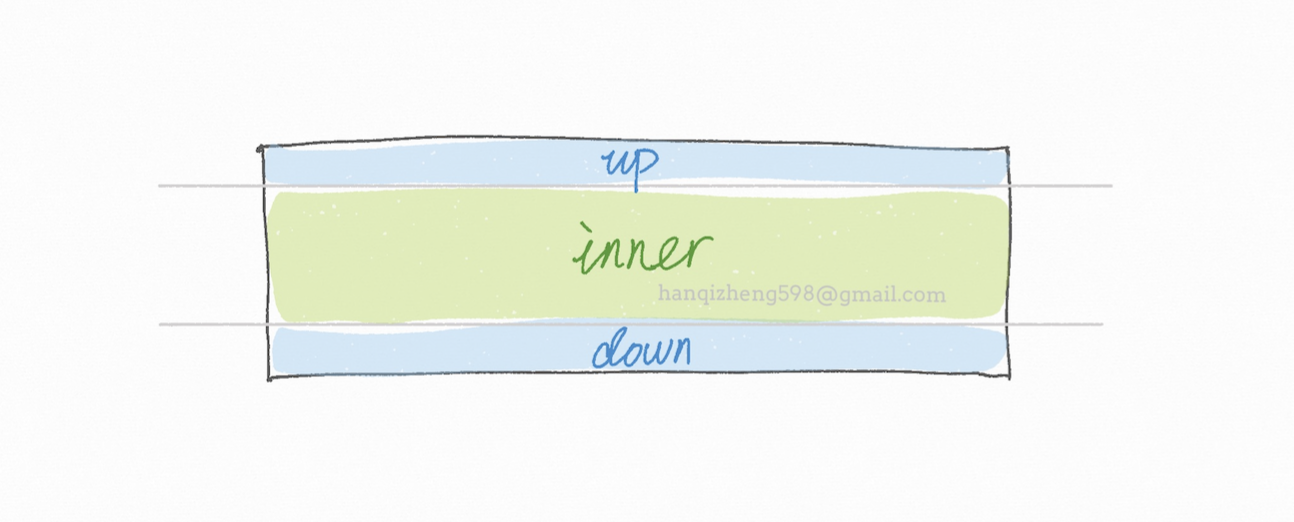
树形结构的拖拽在具体的业务场景中有着不同的拖拽规则,所以作为基础组件,需要告诉使用者:
- 当前拖拽行
- 目标行
- 拖拽触发方式(图中的3种)
有了这些关键信息,组件使用者可以根据具体的业务场景来自行操作数据。